Scaling Natural-Language Video Search: Inside Verkada’s Breakthrough

Security teams don’t have hours to scrub through camera footage. Whether tracing a suspicious vehicle or verifying a delivery, quickly finding the right footage is critical.
In May 2024, Verkada transformed investigations with AI-powered search: a system that understands natural language queries like “FedEx truck on January 15” and returns relevant clips in seconds. It’s a seamless, intuitive experience, and Verkada was one of the first to pioneer it.
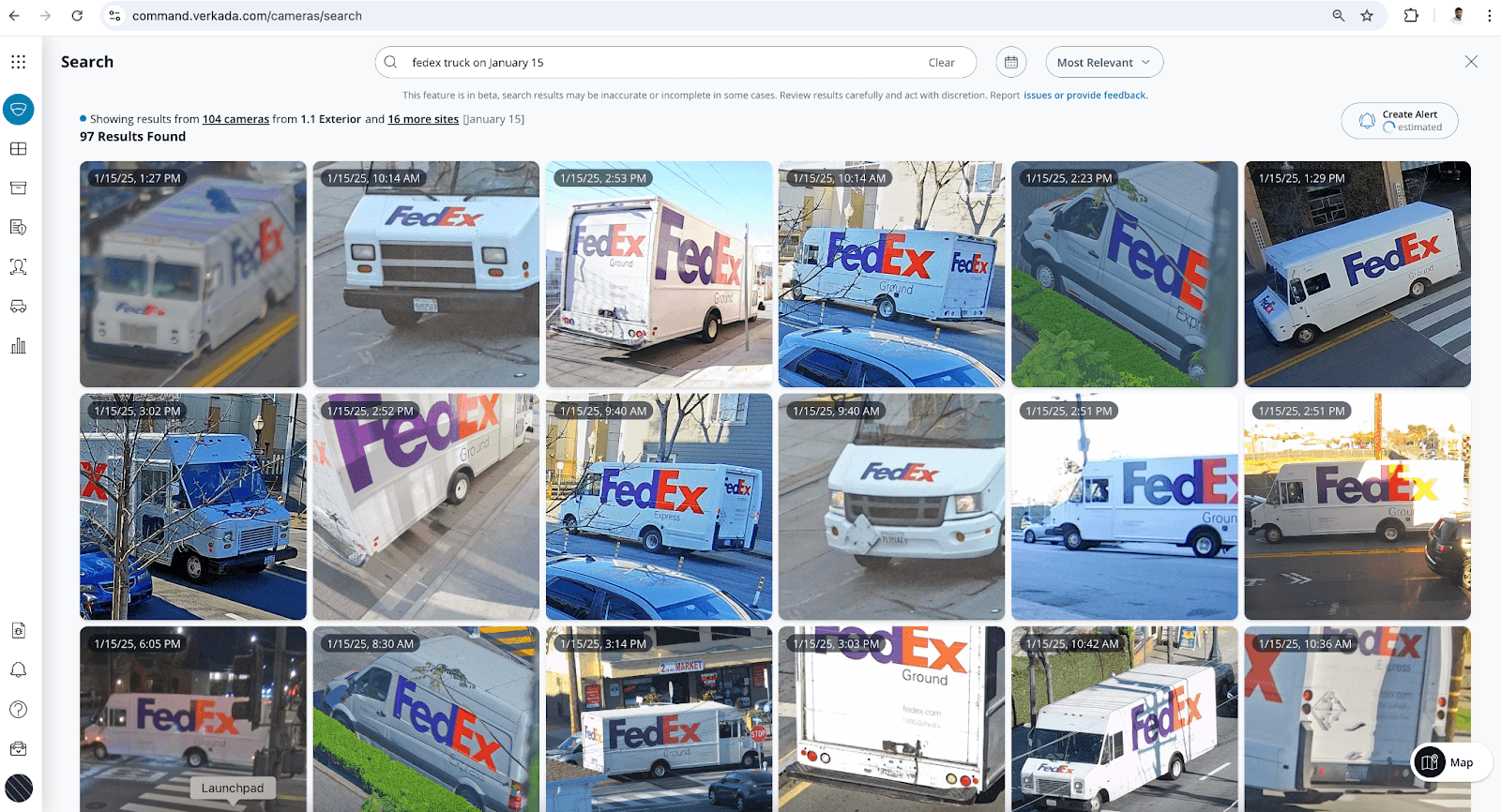
Behind this straightforward search interface lies a technically ambitious system: a custom, time-series-based vector database capable of processing nearly a billion hours of video every month across more than a million devices. We didn’t just make it fast; we engineered it for accuracy, scalability, and cost efficiency. It’s a system that can serve tens of thousands of customers, at scale, without compromising on performance.
Here’s how we built it.
The Engine Behind Natural-Language Video Search
At the heart of this innovation are two key components that work in tandem to deliver AI-powered search at scale:
CLIP-Based Machine Learning Model
We use an open source version of a CLIP (Contrastive Language-Image Pretraining) model, which converts both text (like your search query) and images into a list of floating point numbers, called embeddings. If the text and image are related, their embeddings are highly similar. By comparing embeddings, we can match a query to the corresponding video frames. The model runs on NVIDIA Triton Inference Server for efficient performance.
Custom-Built Vector Database
This is where we store the embeddings generated by the CLIP model. Verkada cameras detect objects—like people or vehicles—and generate high-quality image crops (we call these “hyperzooms”). These cropped images are turned into embeddings using the CLIP model's image encoder and saved in our vector database. When a user performs a natural language search, the system creates an embedding from their query using the CLIP model's text encoder and compares it to stored embeddings to find relevant footage.
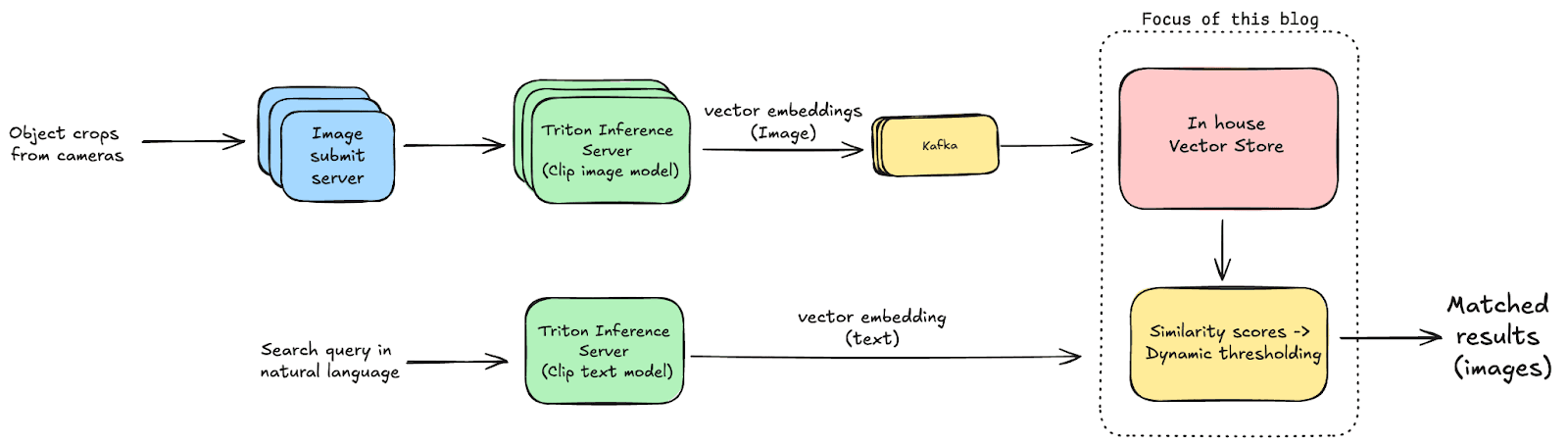
This architecture unlocks intuitive AI-powered search, but while running AI models in the cloud is fairly straightforward these days, the storage system turned out to be non-trivial as existing solutions are built for very different requirements. In this article, we’re going to explore how Verkada built its own vector database to meet unique customer needs.
Why Off-the-Shelf Solutions Weren’t Enough
We couldn’t just plug in an existing solution. Most vector databases are designed for static, read-heavy use cases. We needed the opposite: a system that could ingest close to a billion embeddings a day. We also wanted:
Support for time-based freeform search, like “person wearing a green hat at 4 PM”
Location-based search capabilities to support large organizations with multiple sites
Multi-tenancy so thousands of organizations can share infrastructure but keep their data isolated
Accurate and fast search, even across billions of video frames
Minimal end-to-end latency to enable near-instant availability of search results
Of the vector storage systems we evaluated, most required substantial customizations to meet these requirements. So we built a new vector database from the ground up.
Inside the System: How Verkada Engineered AI Search at Scale
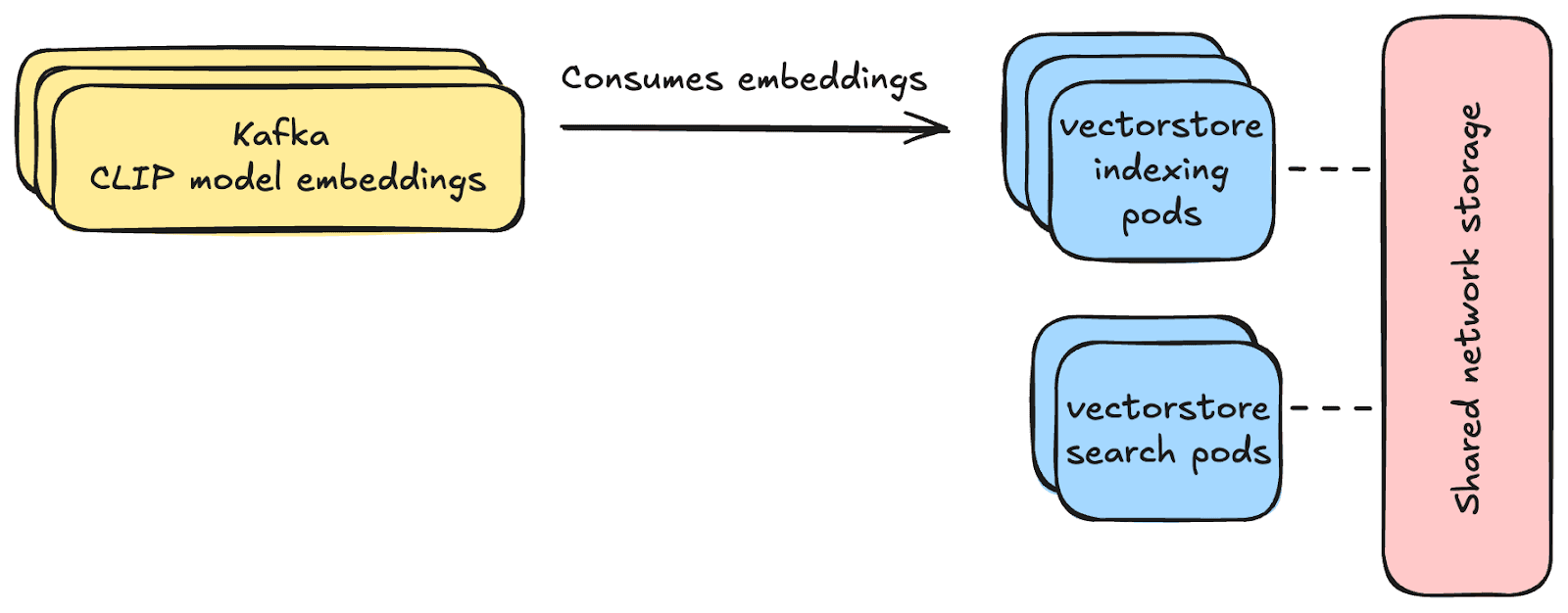
1. Separation of Duties: Indexing vs. Search
To handle massive data throughput without sacrificing search speed, we divided the system into Indexing Pods (optimized for writing) and Search Pods (optimized for querying). This separation allows each layer to scale independently, keeping search performance high, no matter the write load.
Indexing Pods: These handle incoming data. They consume embeddings from Apache Kafka – a distributed event streaming platform that allows for reliable and scalable data ingestion – and write them to shared network storage as NumPy vector files. These pods require fewer CPU and memory resources.
Search Pods: These do the heavy lifting during a search, comparing user query to stored embeddings. They compute the dot product of the query embedding and stored embeddings, which is a CPU heavy task. They scale separately based on how many searches are happening.
2. Hierarchical Data Organization (Multi-Tenancy)
To support high multi-tenancy and time-based searches, rather than relying on a single global index, we store data hierarchically by organization → date → time, enabling fast lookups while maintaining strict tenant isolation. Each day's directory contains time-based segment files stored as NumPy arrays. These segment files vary in duration, with the time span indicated in the file name. This hierarchical structure makes it efficient for search pods to quickly access data without requiring an explicit global data index. It’s a database structure built for speed at high scale.
3. Efficient Data Flow (Kafka Partitioning)
Whether it’s a 3-camera office or a 3,000-camera enterprise, our Kafka partitioning helps ensure fast, efficient ingestion.
For small organizations with less traffic, the organization ID is used as the Kafka partition key. This allows a single pod to write all embeddings for a given organization to a single file, thus avoiding the need for file locks.
For large organizations with heavier traffic, camera ID is the Kafka partition key, so multiple pods can simultaneously write data from different cameras for a given organization. Also, periodic compaction jobs merge camera-specific embedding files into a single, organization-level file. This reduces read disk operations for faster search.
4. Speed & Freshness via In-Memory Optimizations
Indexing pods load embedding data from Kafka into memory and flush batches of embeddings to NumPy files every few seconds instead of doing it constantly. This balances quick search availability with fewer disk writes.
For time-based queries, search pods load only the relevant time segment files based on the requested time range. Then, they use filters like camera ID and object type to narrow results before doing heavy matrix multiplications to compare embeddings.
For searches without a time range, time-based pagination is implemented. The vector database returns results and a token, enabling the user to paginate through the results efficiently.
Frequently accessed data stays cached in memory to speed up repeat searches.
The result: search results in seconds, even for recent events.
5. Recall Matters: Exact k-NN Search
Instead of relying on “approximate” matching (used by many vector databases), we use:
Exact k-Nearest Neighbor (k-NN): A more accurate algorithm to help surface relevant matches.
Dynamic Score Thresholding: Sets the threshold level for what counts as a “match” to maintain accuracy while avoiding false positives.
The Result: AI-Powered Search at Scale
By building the infrastructure from the ground up, we created a system purpose-built for speed, scale, and precision. This foundation now powers one of the most advanced natural language video search systems in the market.
Support for over 31,000 organizations
Handling more than 800 million embeddings every day
Thousands of AI-driven searches daily
Results that return in seconds with exceptional accuracy
We didn’t just build a better way to search security footage. We built a system that rewrites what people expect from physical security platforms. And we're continuing to raise that bar, evolving the system to handle even more nuanced and powerful search experiences.
More Than Innovation: A New Standard for Physical Security
This isn’t just an application of AI, it’s a reflection of deep technical ambition, rigorous cross-functional execution, and a willingness to rethink what’s possible. Verkada is purpose-building novel solutions to deploy AI today at scale in production, not just retro-fitting general-purpose tools into existing security workflows.
Our time-series-based vector database isn’t just an internal milestone. It’s a signal to the market: the future of security is searchable, scalable, and smart. And Verkada is leading the way.
Engineering at Verkada means solving problems that haven’t been solved before. If you’re looking for that kind of challenge, join us.





